一种SkipList的数组实现方法
05 May 2022https://github.com/syndtr/goleveldb/blob/master/leveldb/memdb/memdb.go
数据结构
const tMaxHeight = 12
const nKV = 0
const nKey = 1
const nVal = 2
const nHeight = 3
const nNext = 4
type DB struct {
kvData []byte // 记录kv数据
// Node data数据格式:
// [0] : KV offset
// [1] : Key length
// [2] : Value length
// [3] : Height
// [3..height] : Next nodes,例如height = 3 的节点会有3个next节点
nodeData []int // 节点的index
prevNode [tMaxHeight]int // 记录不同level的前置node index
}
nodeData作为索引,记录每个node在kvData中的offset和kv大小、所在的level,及其所有level上的next node
prevNode在search的时候记录每一层的路径,在insert或delete节点的时候使用
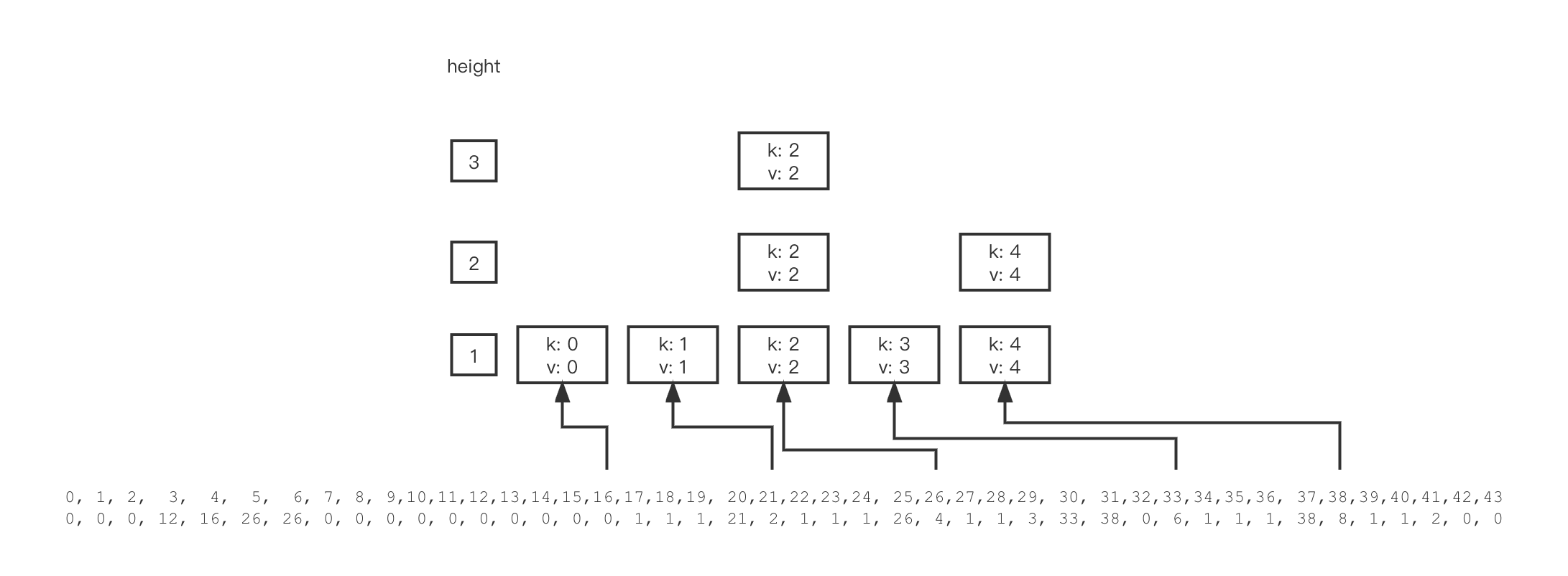
拿 (k:2 v:2) 举例来看,对应的nodeData为4, 1, 1, 3, 33, 38, 0,分别为kvData中的offset、key length、value length、height,每一height level的next node,该node height为 3 所以对应 3 个next值
初始化
nodeData = make([]int, 4+tMaxHeight),nodeData[nHeight] = tMaxHeight,nodeData初始化最高层的记录,这里全部初始化为0
0 1 2 3 4 5 6 7 8 ...
nodeData [ ][ ][ ][12][ ][ ][ ][ ][ ] ...
nodeData[0]相当于root node
操作
-
Get
func (p *DB) findGE(key []byte, prev bool) (int, bool) { node := 0 h := p.maxHeight - 1 // 从nodeData[maxHeight - 1]开始查找,也就是最高level的第一个节点 for { next := p.nodeData[node+nNext+h] // 获取当前level的next节点 cmp := 1 if next != 0 { // 如果有next值则比较大小,否则继续到下一level查找 o := p.nodeData[next] cmp = p.cmp.Compare(p.kvData[o:o+p.nodeData[next+nKey]], key) } if cmp < 0 { node = next // 继续查找 } else { if prev { // 记录当前level的prevNode,在insert或delete的时候需要,需要加锁因为修改共享变量p.prevNode p.prevNode[h] = node } else if cmp == 0 { return next, true } if h == 0 { return next, cmp == 0 } h-- } } } -
Put
func (p *DB) Put(key []byte, value []byte) error { p.mu.Lock() defer p.mu.Unlock() if node, exact := p.findGE(key, true); exact { // 如果key已经才在,替换原有key的kvData offset值以及kv的length kvOffset := len(p.kvData) p.kvData = append(p.kvData, key...) p.kvData = append(p.kvData, value...) p.nodeData[node] = kvOffset m := p.nodeData[node+nVal] p.nodeData[node+nVal] = len(value) p.kvSize += len(value) - m return nil } h := p.randHeight() // 获取新节点的height if h > p.maxHeight { for i := p.maxHeight; i < h; i++ { p.prevNode[i] = 0 } p.maxHeight = h } // 将新节点的值增加到kvData中 kvOffset := len(p.kvData) p.kvData = append(p.kvData, key...) p.kvData = append(p.kvData, value...) // Node node := len(p.nodeData) // 在nodeData中增加新节点的index(KV offset, Key length, Value length, Height) p.nodeData = append(p.nodeData, kvOffset, len(key), len(value), h) // 在0 - h level中插入新增节点 for i, n := range p.prevNode[:h] { // prevNode在之前findGE()中更新,记录该节点在每一level应该插到那个节点之后 m := n + nNext + i p.nodeData = append(p.nodeData, p.nodeData[m]) p.nodeData[m] = node // 类似于链表中间插入节点 } ... return nil } -
Delete
func (p *DB) Delete(key []byte) error { p.mu.Lock() defer p.mu.Unlock() node, exact := p.findGE(key, true) if !exact { return ErrNotFound } h := p.nodeData[node+nHeight] for i, n := range p.prevNode[:h] { // 在每一level中将该节点删除 m := n + nNext + i p.nodeData[m] = p.nodeData[p.nodeData[m]+nNext+i] } ... return nil }