Raft共识算法及其实现
04 Apr 2018在分布式存储系统中往往会在不同机器上储存多份数据副本,有以下几点目的[1]:
- 使数据存储的地理位置离用户更近,从而降低延迟
- 保证在集群的一部分机器发生故障的情况下系统然能正常工作
- 增加可以提供读操作的机器,从而提高读吞吐量
但是在某些应用场景下,用户希望整个系统对外表现一致,像是在一个单机系统上操作,这就引入了多副本间的数据一致性问题。
通过共识算法(consensus algorithm)可以解决多副本一致性问题,最著名的要属Paxos算法,但是Paxos算法有两个比较明显的缺点[2]:比较难理解;工程上难实现。所以Raft是一个更容易理解和实现的共识算法。
共识算法一般是用来管理复制状态机,而复制状态机一般通过日志复制实现,所以Raft就是管理日志复制的算法。Raft会选出一个leader来负责处理用户端请求,以及发起提案,管理日志完整性。我认为Raft最重要的一点性质就是保证leader拥有最全的日志,在有了leader机制后,Raft将问题拆分为三个子问题,就是leader election,log replication和safety,通过对三个子问题的解决,就得到了一个一致性算法。
本文会结合floyd[3]代码介绍Raft算法的实现。
概述
由于我们要解决的是在异步网络模型下一致性问题,数据包可能会乱序、丢失、重复等等,各个节点间的时间不可能同步。所以Raft通过term作为逻辑时钟进行节点间同步,一个term用自然数表示,表示Raft算法内的一段逻辑时间,每个term都从选举操作开始,选举出leader后才能正常提供服务,每个term只有一个leader。Raft在任何时期都会保证以下性质的成立:
- Election Safety:在一个term中只有一个leader
- Leader Append-Only:leader不会覆盖或删除log中的entry,只会添加新entry
- Log Matching:如果两个log包括了一条具有相同index和term的entry,那么这两个log在这个index之前的所有entry都相同。
- Leader Completeness:如果在某一term一条entry被commit了,那么在更高term的leader中这条entry肯定会存在。
- State Machine Safety:如果一个节点将一条entry应用到状态机里,那么任何节点也不会再次将该index的entry应用到状态机里
在任何时期,Raft中的节点都只会处在以下三种状态之一:leader、follower或candidate。follower完全被动,只需要回复leader和candidate节点的请求;leader负责处理用户请求,如果用户请求发送到其他节点会被转发到leader;candidate状态是选举leader期间的特殊状态。不同节点之间通过RPC通信,主要有两种类型的RPC:RequestVoteRPC,AppendEntriesRPC。状态转化如下图所示,所有节点初始化时为follower状态:
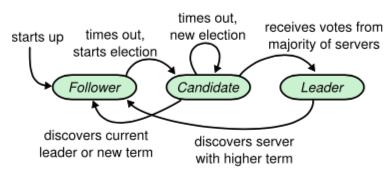
图1:节点状态转换
整个算法流程可以参考论文中的Figure 2。
下面简单介绍一下floyd,floyd是一个C++版的Raft实现,设计初衷是用来管理分布式系统中的元信息。现已用在分布式KV存储系统Zeppelin的Meta节点中,以及pika的多机房同步工具pika_hub中。通过了jepsen的一致性测试。floyd结构框架如下图所示,详细介绍可以参考wiki。
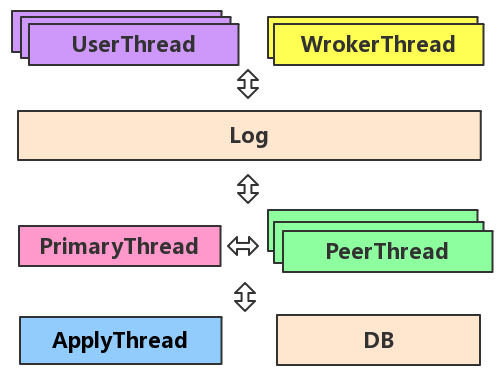
图2:floyd框架结构
Leader election
在一个term内Raft保证只有一个leader,leader节点会定期向所有follower 发送心跳(通过不带entry的AppendEntriesRPC),如果follower在一定时间没有收到来自leader的心跳, 就认为当前term的leader已经发生故障,自己会将当前term增加一同时转换为candidate状态然后发起投票,首先会投自己一票,然后通过RequestVoteRPC向其它所有节点发送投票请求。
在floyd中节点的term、超时时间等信息在FloydContext类中存储,其中term需要持久化。节点初始化后会在FloydPrimary类中添加CheckLeader任务,当然只有follower和candidate节点会执行。
file: src/floyd_primary_thread.cc
101 void FloydPrimary::LaunchCheckLeader() {
...
103 if (context_->role == Role::kFollower || context_->role == Role::kCandidate) {
104 if (options_.single_mode) {
...
111 } else if (context_->last_op_time + options_.check_leader_us < slash::NowMicros()) {
112 context_->BecomeCandidate(); // 发起选举,并投自己一票
...
116 raft_meta_->SetCurrentTerm(context_->current_term); // 持久化当前状态
117 raft_meta_->SetVotedForIp(context_->voted_for_ip);
118 raft_meta_->SetVotedForPort(context_->voted_for_port);
119 NoticePeerTask(kHeartBeat); // 向其他节点请求投票
120 }
接下来可能会发生三种情况,a)该节点赢得选举,b)另一个节点成为了leader,c)在一段时间后仍没有结果。
a):一个节点赢得选举指的是收到了过半数节点的投票。每个节点在一个term内只能投一个节点,会根据1)投票请求到达的顺序;2)只投给拥有比自己更新日志的节点,这两个限制条件进行投票(Safety)。
floyd中在leader端用PeerThread抽象每一个follower,相应的RequestVoteRPC也在该线程中进行。
file: src/floyd_peer_thread.cc
93 void Peer::RequestVoteRPC() {
...
143 if (res.request_vote_res().vote_granted() == true) { // 收到该节点的投票
...
148 if (CheckAndVote(res.request_vote_res().term())) { // 检查是否收到过半数的投票
149 context_->BecomeLeader(); // 称为leader
150 UpdatePeerInfo();
...
153 primary_->AddTask(kHeartBeat, false); // 添加发送心跳任务
154 }
155 } else {
...
159 context_->BecomeFollower(res.request_vote_res().term()); // 该节点拒绝投票
160 raft_meta_->SetCurrentTerm(context_->current_term); // 成为follower
161 raft_meta_->SetVotedForIp(context_->voted_for_ip);
162 raft_meta_->SetVotedForPort(context_->voted_for_port);
163 }
b):在candidate等待投票结果时,可能会收到其它节点的AppendEntrieseRPC,如果RPC的term大于等于自己的term,那说明已经有leader被选举出来了,此时需要更改自己的状态称为新leader的follower。如果RPC的term比自己小,会直接抛弃。
file: src/floyd_impl.cc
785 int FloydImpl::ReplyAppendEntries ...
...
793 if (append_entries.term() < context_->current_term) { // 抛弃过期RPC
...
798 return -1;
799 } else if ((append_entries.term() > context_->current_term)
800 || (append_entries.term() == context_->current_term &&
801 (context_->role == kCandidate || (context_->role == kFollower && context_->leader_ip == "")))) {
...
806 context_->BecomeFollower(append_entries.term(),
807 append_entries.ip(), append_entries.port()); // candidate收到leader的心跳,
808 raft_meta_->SetCurrentTerm(context_->current_term);// 成为follower
809 raft_meta_->SetVotedForIp(context_->voted_for_ip);
810 raft_meta_->SetVotedForPort(context_->voted_for_port);
811 }
c):有多个节点发起投票了,但投票被均分了,无法决定谁是leader,此时需要每个节点重新超时重新发起新一轮投票。可以通过设置随机超时时间来尽可能避免这种情况发生。
Log replication
当leader选出来之后就可以为客户端提供服务了,每条客户端请求都可能会改变复制状态机,leader首先将当前term与请求内容组成一条entry添加到log中,随后并行调用AppendEntriesRPC将新entry发送给其它follower,当entry被过半数的节点收到并添加到自己的本地日志后,leader就可以commit这一条entry,在floyd中,FloydContext::commit_index指针表示当前已经commit的entry,这些entry可以应用到状态机,在apply之后就可以返回给用户。Raft规定已经commit的entry需要保证永远存在。
对于follower,完全处于被动状态,收到leader通过AppendEntriesRPC发送来的entry,需要比较leader的prev_log_index和自己的,如果比自己的大,说明自己没有追齐leader的日志,但leader并不知道,要回复自己的index让leader调整发送。如果比自己的小或者term和自己的不一样,说明可能选出了一个新leader,并且自己的最后一个log还没有commit,可以直接覆盖掉。都没有问题的话就将entry添加到自己的日志中,在floyd实现中,如果leader的commited_index比自己的大,那自己也可以进行commit,但这里的commit只是follower的行为,指的是follower节点可以将此前的日志apply到本地状态机中。
从上述行为可以看出,日志复制行为完全由leader主导进行,保证了数据是从leader流向follower。commit机制保证了数据会在过半数节点中存在,就算重新选举,也能保证在任意过半数的节点中至少一个节点存在这个数据。
Safety
通过以上两个子问题已经可以解决绝大多数场景,但是还有两个细节需要考虑:
- 再重新选举时,需要保证新leader拥有最新的log,所谓最新指的是,如果两条日志的term不一样,那么term大的较新,如果term一样,那么index大的较新。
- leader在commit时只对本term的entry采用统计大多数的方式commit。
关于第一点,也就是在前文leader election中投票限制的第二个条件,由于称为leader需要投票过半,而任意过半数的节点们(由于commit机制)一定会有一个拥有最新日志的节点,也就保证了它肯定会被选为leader。
第二点比较复杂,考虑下图中(c)的情况,这时S1被选为了term4的leader,并接收了index3,同时开始将index2复制到其它follower,在半数成功后,如果这时commit了index2,就是表明index2可以持久化到状态机中,但在这时S1宕机,S5被选为leader,它所拥有的term3日志将会把之前commit的index2给覆盖掉,这是错误的。
由于在(c)中index2虽然被过半数的节点接收,但是当前leader的term是4,所以即使是过了半数节点接受了此日志也不能commit,只有像在(e)情况下,待index3过了半数接收,成功commit后就相当于将此之前的log都commit了。这时就算重新选举,S5也不会称为leader,也就不会发生已经commit过的日志被覆盖掉的情况。这就是第二点所说的只有当前term才能通过统计大多数进行commit。
还有一点要提的是,在(a)中,S1作为leader,客户端写入了index2并等待回复,这时S1宕机,客户端没有得到明确的回复,那么其实index2有可能成功,也有可能不成功,这就是第三态返回值,在理解线性一致性(linearizability)问题中可能会用的到。
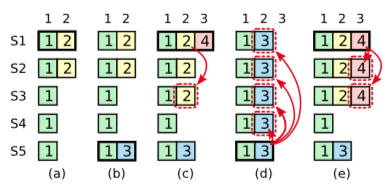
图3:Raft Safety
安全性证明
论文中证明了Raft在强leader下保证安全性机制的正确性,首先假设Leader Completeness性质不存在,假设term T的leader($leader_T$)提交了一条entry,但在未来的某一时刻entry不在这个leader里。那么下一term U(U > T),并且$leader_U$不存在这一条entry。证明:
- 由于leader不会删除或覆盖log,那么在$leader_U$被选为leader的时候已经提交的entry肯定存在于$leader_U$中
- $leader_T$将entry复制到了半数以上的节点中,$leader_U$是由半数以上的节点投票产生。所以至少会有一个节点,既接受了$leader_T$的entry,也投票给了$leader_U$,这里是产生矛盾的关键点。
- 这个节点肯定是在投票给$leader_U$之前接受了$leader_T$的entry;否则就会拒绝$leader_T$的AppendEntriesRPC,因为投票给$leader_U$之后它的term会大于T。
- 这个节点在投票给$leader_U$时会持有这个entry。
- 这个节点投票给$leader_U$的话,$leader_U$就必须有和投票者一样或更新的日志。这里导致了第一个矛盾点。
- 首先,如果$leader_U$的最后一条log term和投票者一样,那$leader_U$的日志必须会和投票者至少一样长,因此他的log包含了投票者的log。这是其中一个矛盾点,因为投票者有已提交的entry,但是$leader_U$认为自己没有。
- 再者,$leader_U$最后一条log的term必须大于投票者,就是要大于T。那么之前的在$leader_U$之前的leader中一定有这个已经提交过的entry。由于Log Matching性质,$leader_U$中肯定有已提交过的entry,导致了第二个矛盾点。
参考
- 《Designing Data-Intensive Applications》,Martin Kleppmann,O’Reilly Media,2017-4-2
- In Search of an Understandable Consensus Algorithm
- https://github.com/PikaLabs/floyd
- Raft和它的三个子问题